正则表达式(Regular expression )是一组由字母和符号组成的特殊文本,我们常使用缩写的术语“regex”或“regexp”来表示,是学习主流编程语言如 Java、Python、JavaScript 甚至 Shell 都绕不开的话题,它可以用来从文本中找出满足你想要格式的句子。
一个正则表达式是一种从左到右匹配主体字符串的模式。正则表达式可以从一个基础字符串中根据一定的匹配模式替换文本中的字符串、验证表单、提取字符串等等。
例如,登录注册业务中,我们可以利用正则表达式来验证用户名和密码的输入格式是否正确;小说采集业务中,我们可以利用正则表达式来提取网页字符串中的小说名、小说作者、小说封面URL等小说信息,并且通过广告代码的正则表达式替换小说内容中插入的广告代码为空字符串(“”)来实现广告内容的过滤。
以下是一个验证用户名(含字符、数字、下划线和连字符,长度限制为 3-15 个字符)的正则表达式:
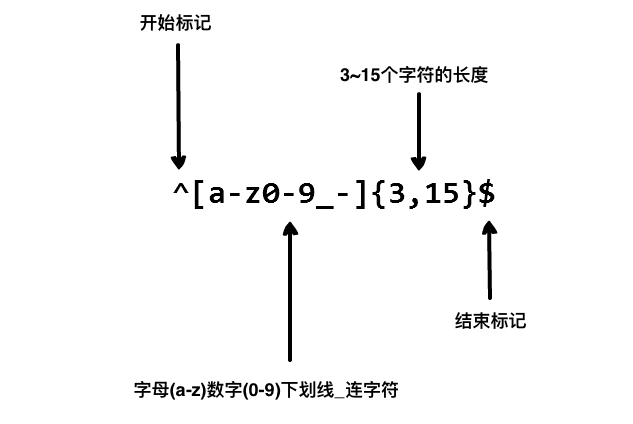
以上的正则表达式可以接受 john_doe、jo-hn_doe、john12_as。 但不匹配 Jo,因为它包含了大写的字母而且太短了。
对于初学者来说,学习正则表达式有两大困难,一是正则表达式包含的符号种类多,如果死记硬背,学习起来非常痛苦;二是正则表达式的中文资源少,介绍混乱,不利于系统学习。learn-regex 开源项目正是一个用来系统学习正则表达式的教程,包含中文、英文、日文、韩文等 10 多种语言的翻译版本。所有内容都包含在一个 Markdown 文档中,不足 500 行,非常简短,很快就能学完,大纲如下:

learn-regex还提供了在线练习,可以直观地展示正则表达式的匹配方式。以下是一个从小说网页字符串中提取小说名的例子:
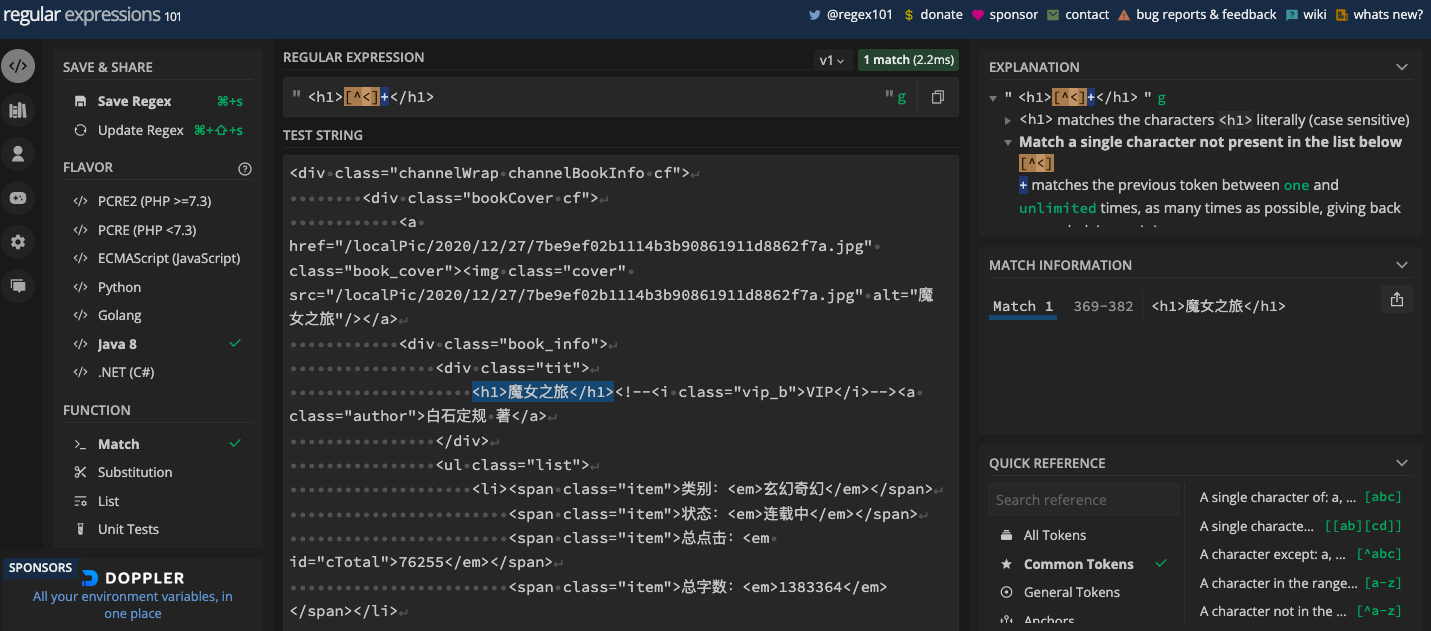
上图中,FLAVOR区域可以选择具体的编程语言,FUNCTION区域可以选择具体的功能(包括匹配、替换等),EXPLANATION区域给出了正则匹配的详细说明,MATCH INFORMATION区域则直接显示匹配的结果,整个布局非常直观且容易理解。